
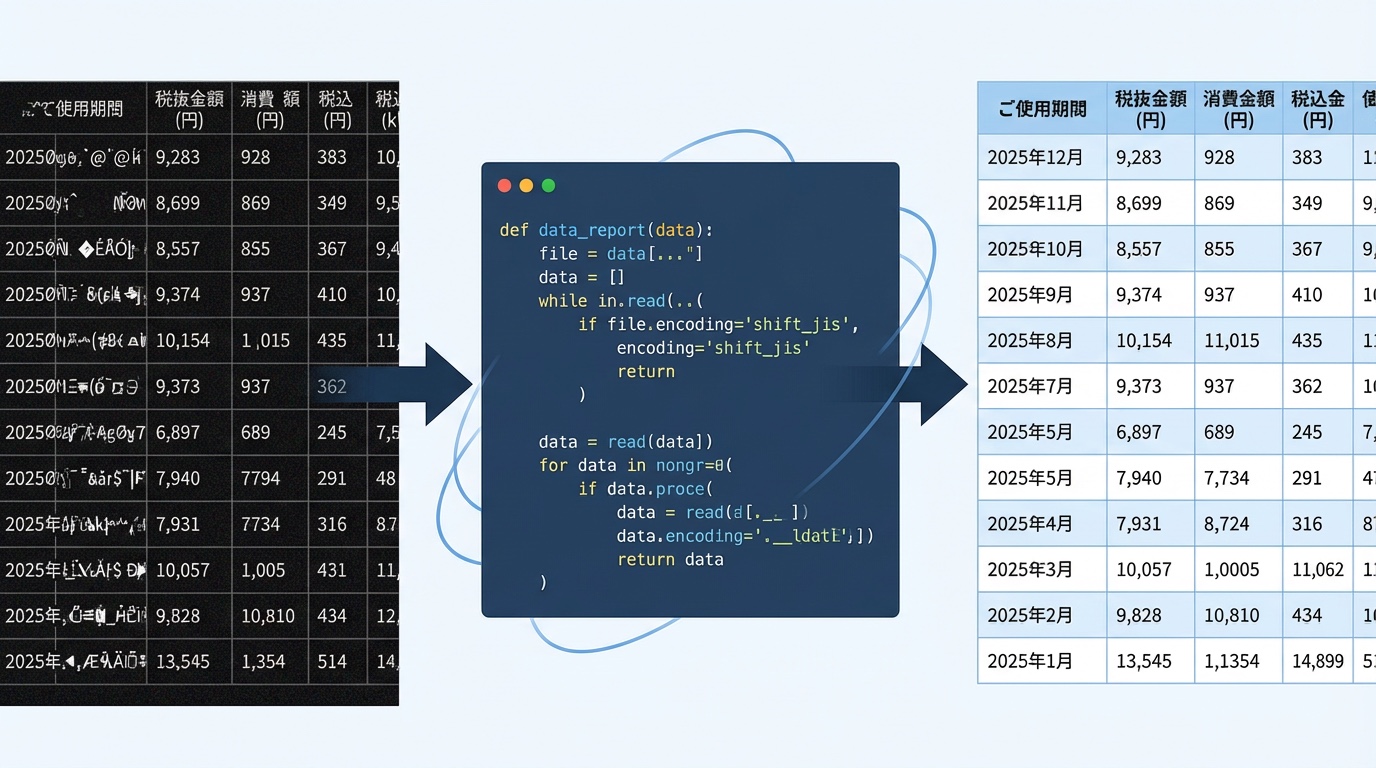
CSVを扱っていると、「Excelでは普通に開けるのに、Pythonだと読み込みエラーになる」という状況に出くわすことがあります。
この記事では、CSVの文字化け問題を解消するために、 Pythonで前処理用のスクリプトを作った話を紹介します。
毎回その場しのぎで直すのではなく、最初にエンコーディングを揃えてしまうことで、その後のCSV処理を安定させる、という考え方です。
実際に、この前処理用のコードを ChatGPTと一緒に作った ので、プロンプトとスクリプトをそのまま載せています。
- Excelでは問題なく開けるCSVを、Pythonで扱うとエラーや文字化けに悩んだことがある
- Pythonは本職ではないが、業務や個人用途で使っている
- ChatGPTにコードを書かせたことがある
- CSV処理を、毎回その場しのぎで直している
1|PythonでCSVを読み込むと文字化けする理由
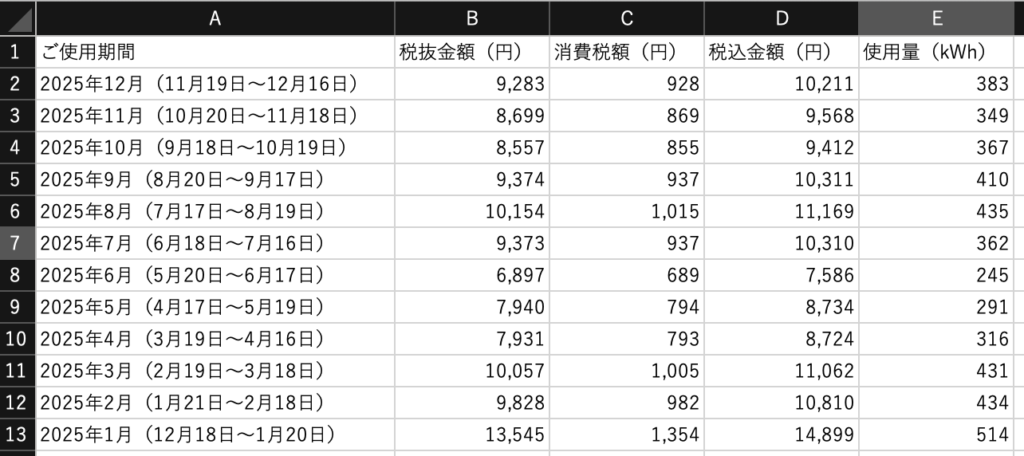
システムからダウンロードしたCSVデータ(ここでは、電力消費量と請求情報データ)対象としています。
ダウンロードしたCSVデータを使用してグラフを作成する以前に作ったPythonスクリプトで処理しようとしたところ、次のエラーがでて先に進みませんでした。
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x82 in position 1: invalid start byte状況を整理すると、問題は次のような点にあると考えられました。
- ダウンロードしたCSVは、Excelで開くと普通に読めます
- 同じCSVでも、VS Codeで開くと文字化けして見えます

- Pythonで読み込むと、文字化けした内容として扱われるか、エラーになって先に進みません
- 以前に書いた自分のスクリプトでは、すでにエンコーディング指定はしていました
- それでも問題が起きたのは、指定していたエンコーディングと、今回のCSVの実体が一致していなかった可能性が高いです
- Excelは文字コードの自動判定や吸収が強く、問題が表に出にくいようです
- 一方でPythonは、前提がズレていると、そのズレがそのままエラーや文字化けとして現れます
ここまでの切り分けから、Excelでは問題なく扱えていた一方で、VS Code や Python ではうまく処理できなかったことを考えると、エンコーディングが原因である可能性は高いと考えました。
実は、
動かしたいスクリプトを作ったときにも、まったく同じ問題に直面していたことを思い出しました。
毎回ここでハマってしまうため、この問題を前提から片づける目的で、CSVの前処理用スクリプトを作ることにしました。
2|毎回起きるCSV文字化けを「前処理」で解決する考え方
ここまでの切り分けから、問題はPythonのコードそのものではなく、Pythonが読むCSVの状態が、毎回バラバラなまま処理していたことにあると感じました。
外部からダウンロードしたCSVを扱っていると、
- 文字コードが毎回違う
- どのエンコーディングで書かれているか分からない
- その結果、同じところで何度も詰まる
といった状況が起きがちです。
そこで考え方を変えて、
「Pythonが読むCSVのスタンダードを、最初に決めてしまう」
ことにしました。
具体的には、
- CSVをそのまま処理に流さない
- 処理に入る前に、Pythonによる前処理として、エンコーディングを正規化する
- Pythonが扱うCSVは、品質がそろったCSVだけを扱う
という流れです。
一度この前処理を入れてしまえば、CSVの文字コードを毎回疑う必要はありません。
CSVの文字化け問題を、毎回発生するトラブルから最初に品質をそろえておく作業に移す、という考え方をとることにしました。
次は、この前処理をどのようなプロンプトでChatGPTに依頼し、どんなPythonスクリプトになったのかを見ていきます。
3|ChatGPTに渡したプロンプトとPythonスクリプト
ここまでで、「Pythonが読むCSVのスタンダードを、先に決めておく」という方針は固まりました。
次は、それを どう実装したか です。
今回は、この前処理用のスクリプトをChatGPTに相談しながら作りました。
といっても、専門的な指示や難しい言い回しはしていません。
実際にChatGPTに伝えたのは、次のような内容です
- CSVの文字コードが毎回バラバラで困っている
- Pythonで処理する前に、文字コードをそろえたい
- どんなCSVが来ても、UTF-8 with BOM に正規化したい
要件としては、この程度でした。
この内容をそのまま投げるだけで、前処理用のPythonスクリプトのたたき台が一気に出てきました。
もちろん、一発で完成したわけではありませんが、ゼロから自分で設計する必要がなかったという点で、体感的な負担はかなり小さくなりました。
非エンジニアでも、「やりたいこと」を日本語で整理して伝えれば、実務で使えるコードの形まで持っていける。
この一連の流れは、AI × Python の実用的な使い方をそのまま表していると感じています。
次は、ChatGPTと一緒に仕上げたCSV前処理用のPythonスクリプト全文を紹介します。
4|【コピペOK】CSV文字化け対策の前処理Pythonコード全文
ここまでで整理した
「Pythonが読むCSVのスタンダードを先に決める」
という考え方を、そのまま形にしたのが、この前処理スクリプトです。
- 外部からダウンロードしたCSVを、そのまま処理に渡さない
- どの文字コードで書かれていても、一度読み直す
- 必ず UTF-8 with BOM に正規化してから、後続の処理に渡す
こうすることで、後続のPython処理では「このCSVは何の文字コードだろう?」と毎回疑う必要がなくなります。
- CSVファイルを、まずはバイト列として読み込む
- 複数のエンコーディングを順に試し、正しく読めるものを探す
- 読めた内容を **UTF-8 with BOM(utf-8-sig)** に変換する
- 正規化したCSVを出力用フォルダに書き出す
- 以降のPython処理では、文字コードを意識せずにCSVを扱える状態にする
この前処理を一度噛ませておけば、CSVの文字化け問題は毎回発生するトラブルではなく、最初に片づけておく前提作業になります。
以下が、実際に使っている前処理用のPythonスクリプトです。
#!/usr/bin/env python3
"""csv2utf-8-sig.py
目的:
- プロジェクト配下のCSVを読み取り、UTF-8 with BOM(utf-8-sig)に正規化して `result/` に出力する。
仕様:
- 入力フォルダはデフォルトで `data/`。
- ただし `data/` が存在しない、またはCSVが見つからない場合はプロジェクト直下(このpyと同階層)を探す。
- 読み込みは複数エンコーディングを順に試す(utf-8-sig/utf-8/cp932/shift_jis/euc_jp/latin1)。
- 出力は常に utf-8-sig。
使い方:
python csv2utf-8-sig.py
python csv2utf-8-sig.py --in ./some_folder --out ./result
"""
from __future__ import annotations
import argparse
from pathlib import Path
ENCODINGS_TO_TRY = [
"utf-8-sig",
"utf-8",
"cp932", # Windows日本語(Shift_JIS系)
"shift_jis",
"euc_jp",
"latin1", # 最後の手段(壊れないが文字化けの可能性あり)
]
def read_text_with_fallback(path: Path) -> tuple[str, str]:
"""複数エンコーディングを試してテキストとして読む。
Returns:
(text, used_encoding)
Raises:
UnicodeDecodeError: どのencodingでも読めない場合
"""
last_err: Exception | None = None
# まずはバイトで読み込む(改行コード/文字コードの揺れ対策)
data = path.read_bytes()
for enc in ENCODINGS_TO_TRY:
try:
text = data.decode(enc)
return text, enc
except UnicodeDecodeError as e:
last_err = e
continue
# どうしてもダメなら replace で強制(失敗はしないが、文字は壊れる可能性あり)
# ※ ここまで来るのは稀。運用上はこのログを見て元CSVを確認する。
text = data.decode("cp932", errors="replace")
return text, "cp932(errors=replace)"
def normalize_csvs(input_dir: Path, output_dir: Path) -> int:
"""input_dir 内のCSVを utf-8-sig に変換して output_dir に出力する。"""
output_dir.mkdir(parents=True, exist_ok=True)
csv_paths = sorted([p for p in input_dir.glob("*.csv") if p.is_file()])
converted = 0
for src in csv_paths:
text, used_enc = read_text_with_fallback(src)
dst = output_dir / src.name
dst.write_text(text, encoding="utf-8-sig", newline="")
print(f"OK : {src.name} ({used_enc} -> utf-8-sig) -> {dst}")
converted += 1
return converted
def main() -> None:
script_dir = Path(__file__).resolve().parent
parser = argparse.ArgumentParser(description="Convert CSV(s) to UTF-8 with BOM (utf-8-sig) and write to result/")
parser.add_argument("--in", dest="in_dir", default=str(script_dir / "data"), help="Input directory (default: ./data)")
parser.add_argument("--out", dest="out_dir", default=str(script_dir / "result"), help="Output directory (default: ./result)")
args = parser.parse_args()
in_dir = Path(args.in_dir).resolve()
out_dir = Path(args.out_dir).resolve()
# 1) デフォルト data/ を試す
tried_dirs: list[Path] = []
if in_dir.exists() and in_dir.is_dir():
tried_dirs.append(in_dir)
converted = normalize_csvs(in_dir, out_dir)
if converted > 0:
print(f"\nDone: converted {converted} file(s). Output: {out_dir}")
return
else:
print(f"INFO: No CSV found in {in_dir}")
else:
print(f"INFO: Input dir not found: {in_dir}")
# 2) data/ が無い or 空なら、プロジェクト直下(このpyと同階層)を試す
fallback_dir = script_dir
if fallback_dir not in tried_dirs:
converted = normalize_csvs(fallback_dir, out_dir)
if converted > 0:
print(f"\nDone: converted {converted} file(s). Output: {out_dir}")
return
# ここまで来たら、どこにもCSVが無い
print("\nNG : CSV file not found.")
print(f" Put .csv files in {in_dir} or {script_dir}, then run again.")
if __name__ == "__main__":
main()こちらのスクリプトで処理すると文字化け問題は解消されました。

このCSVを使って再度動かしたいスクリプトを実行すると問題なく処理されました。
5|補足:CSVとエンコーディング
ここまでで、CSVの文字化けには「エンコーディング」が関係していそうだ、ということを書いてきました。
ここでは、CSVとは何か/なぜ「読めたり読めなかったり」するのかを、整理していきます。
CSVとは
CSVは、カンマ区切りでデータを並べた、とてもシンプルなテキストファイルです。
そのため、
- 中身はただの文字の並び
- 「どういう形式で書かれているか」は、ファイルを見ただけでは分かりにくい
という特徴があります。
エンコーディングとは
エンコーディングは、
「このCSVは、こういう読み方をしてください」
という指定のようなものです。
たとえば、
- 同じ見た目のディスクでも
- CDとして読むのか、DVDとして読むのかで
- 再生できたり、できなかったりする
そんなイメージに近いと思います。
Excelでは普通に開けるのに、PythonやVS Codeではうまく読めない場合、Excelがうまく判断して表示しているだけというケースがよくあります。
今回のポイント
CSVはテキストファイルなので、
- CSVが「どういう形式で書かれているか」
- Pythonが「どういう形式だと思って読もうとしているか」
この2つがズレると、文字化けやエラーになります。
そのため、この記事のスクリプトがやっていることはシンプルです。
- CSVの形式は毎回同じとは限らない
- Pythonは自動で読み方を合わせてくれない
- だから、最初に「読める形」にそろえておく
今回の前処理は、
CSVを処理に渡す前に、必ず「Pythonが読める形」に整える
ためのものです。
これによって、CSVの文字化けや読み込みエラーに、毎回悩まされずに済みます。
6|まとめ:CSV前処理を一度作れば安定運用できる
CSVの文字化けは、一度起きると何度も同じところでつまずきがちです。
今回のように、
処理の前にCSVを「Pythonが確実に読める形」にそろえておく
という前処理を入れておけば、同じトラブルで悩み続ける必要はなくなります。
この対応は、派手な自動化ではありませんが、実務を安定させるための「守り」のPythonとしては、とても効果があります。
また、今回の前処理スクリプトも、ゼロから自分で設計したわけではありません。
- 何に困っているか
- どういう状態にしたいか
を整理してChatGPTに伝えることで、実務で使えるコードを短時間で形にすることができました。
非エンジニアでも、AIをうまく使えば、こうした「毎回ハマるポイント」を仕組みとして片づけることができます。
CSV処理で同じようなストレスを感じている方の、一つの参考になれば幸いです。
【広告(PR)】
今回紹介したCSVの前処理スクリプトもそうですが、筆者自身、Pythonは「最初から体系的に学んだ」というより、実務で困ったところを、AIや資料を頼りに補いながら使っているというスタイルです。
ただ実務で使っていると、
- エラーが出たときに、どこを見ればいいのか
- このコードは何をしているのか
といった 最低限の理解が必要になる場面、ありますよね。
そうしたときに、非エンジニア向けに「実務で使うところだけ」を扱っている教材があると、助けになるかもしれません。
▶︎ Webスキル全般の中でも、実務向けPythonを扱っているオンライン講座はこちら(『デイトラ』で仕事につながるWebスキルを身につけよう!
![]() )
)








